18a La ligne de commande – Grec et Hebreu |
|
La plupart des procédures de recherche en grec, en hébreu ou en araméen sont analogues à celles décrites dans l’introduction de la ligne de commande et valables pour les langues occidentales. Il y a toutefois quelques différences qu’il faut connaitre pour obtenir de meilleurs résultats. Tel est le but de la présente section.
Introduction à la morphologie des bases de données
Doing Command Line Greek and Hebrew Word Searches
Greek and Hebrew Morphological Searches
Searching on Accents and Vowel Points
Including Vowel Points in Hebrew Searches and Accents in Greek
Hebrew Morphological Searches - Qere and Kethib codes
Lemma Agreement and Compound Word Forms
Context Dependency in GNM Searches
Doing Verse Context Sensitive Searches in Hebrew
The Morphology Assistant
Introduction à la morphologie des bases de données ou An Introduction to Morphology Databases
La première chose à comprendre est que, à de rares exceptions près, les bases de données du grec, de l'hébreu et de l'araméen sont disposées par paires. Une base de données contient le texte tel qu’on peut le voir dans la version imprimée. On parle alors de "la base de données du texte". L'autre base de données contient une entrée pour chaque mot du texte. L'entrée est composée d'un thème et d'une chaîne de codes qui donnent des informations sur l'analyse du mot. Le lemme et la chaîne sont séparées par le signe @ pour le grec et l'hébreu et % pour l’araméen. Cette seconde base de données est appelée " base de données de la morphologie".
Ainsi, le texte de la version grecque d’Ac 16,31 apparaîtra de la manière suivante :
oi` de. ei=pan( Pi,steuson evpi. to.n ku,rion VIhsou/n kai. swqh,sh | su. kai. o` oi=ko,j souÅ
Tandis que la morphologie du même passage (selon la Friberg Morphology GNM) donnera :
o`@dnmp^apdnm-p de,@ch ei=pon@viaa--3p pisteu,w@vmaa--2s evpi,@pa o`@dams ku,rioj@n-am-s VIhsou/j@n-am-s kai,@cs sw, | zw@vifp--2s su,@npn-2s kai,@cc o`@dnms oi=koj@n-nm-s su,@npg-2s
Le "texte" de la base de données correspond au texte "imprimé". La morphologie, pour sa part, rend compte de l’inflexion des lemmes et de leur racine originelle. Par exemple, la forme Pi,steuson dans le texte correspond à pisteu,w dans la morphologie. Les abréviations vmaa - 2s après le lemme pisteu,w signifient que Pi,steuson est un verbe de mode impératif, temps aorist, voix active, 2e personne du singulier et qu'il vient du lemme pisteu,w.
Maintenant, supposons que l’on veuille trouver toutes les occurrences où le verbe pisteu,w (croire) est conjugué à l’impératif (c'est-à-dire comme un commandement). Rechercher pi,steuson dans le texte de base de données ne fournirait malheureusement que les seules occurrences de cette forme qui est au singulier. Mais si l’on souhaite tous les impératifs, singuliers et pluriels, il faut effectuer la recherche à partir de la morphologie et non du texte. La recherche pourrait se présenter ainsi sur la ligne de commande :
|
.pisteu,w@vm?a--2? |
Dans cet exemple, nous avons juste remplacé les codes
représentant le temps et le nombre par un ? afin de trouver tous les
impératifs indépendamment du temps ou du nombre.
Un résumé des codes utilisés est disponible dans la
section Schémas
de codage morphologique.
Cet exemple a simplement pour but de montrer l’importance de la recherche
à partir de la morphologie en grec et en hébreu. La
méthode peut paraître complexe au début, mais avec un peu
de pratique, n'importe qui ayant une connaissance élémentaire de
la langue d'origine peut accéder à la richesse des informations
que ces bases de données fournissent.
 Apprentissage des codes
ou Learning the
Codes
Apprentissage des codes
ou Learning the
Codes
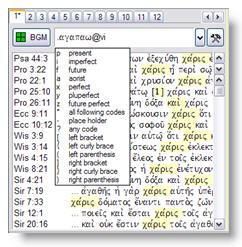
Pour effectuer une recherche morphologique les
«mots» saisis dans la ligne de commande doivent êtres
composés d'un thème et d'un code morphologique
séparés par un "@" ou "%". BibleWorks
possède différents modules d’aide pour l'apprentissage et
la construction de ces codes. Dans la ligne de commande, par exemple, au fur et
à mesure de la saisie, une aide intuitive propose, sous la forme
d’un menu déroulant, la suite possible du code. On peut toutefois
désactiver cette fonctionnalité en cliquant sur le bouton Setup
Windows ![]() puis Option
Flags | Command Line Configuration Options | Enable Command Line Morphology
Code Help.
puis Option
Flags | Command Line Configuration Options | Enable Command Line Morphology
Code Help.
La fenêtre lexicale du GSE possède également un assistant
de morphologie qui intervient lui aussi étape par étape dans la
construction du code.
As indicated earlier most Greek and Hebrew Morphology Databases come in matched pairs. For example the GNM is the morphological database for the GNT (UBS 4th Greek New Testament) and the BNM is the morphological database for the BNT (NA 27th Greek New Testament). The matched pairs that ship with BibleWorks currently are:
|
BNT/BNM |
NA27 Greek New Testament and BibleWorks Morphology |
|
GNT/GNM |
UBS4 Greek New Testament and Friberg Morphology |
|
BGT/BGM |
Combined BLM/LXT and BNM/BNT |
|
LXT/BLM |
BibleWorks LXX Text and Morphology |
|
SCR/SCM |
Scrivener's Greek New Testament and Morphology |
|
TIS/TIM |
Tischendorf's Greek New Testament and Morphology |
|
BYZ/BYM |
Robinson-Pierpont Greek New Testament and Morphology |
|
WHO/WHM |
Westcott-Hort Greek New Testament Text and Morphology |
|
STE/STM |
Stephanus Greek New Testament Text and Morphology |
|
VST |
von Soden Greek New Testament (no morphology yet) |
|
TAR/TAM |
Targumim Text and Morphology |
|
WTT/WTM |
BHS Hebrew Old Testament and Morphology |
|
APF/APM |
The Apostolic Fathers |
|
JOS/JOM |
The Works of Josephus |
|
PHI/PHM |
The Works of Philo |
The individual databases in these pairs are sometimes referred to in the documentation as "brother" or "companion" texts of the other part of the pair.
Doing Command Line Greek and Hebrew Word Searches
If you have chosen the Greek New Testament, Septuagint, or Hebrew OT as your search version, the search will be in Greek or Hebrew. The fonts in the Word List Box and on the Command Line will change automatically to Greek or Hebrew as needed. Note that you type Hebrew just as you would in a Hebrew word processor. Text will be displaced to the right as you type. Searches in Hebrew/Greek are normally done on the unpointed/unaccented texts, so don't type in any vowel points or accents unless vowel point searching is enabled (see below). Keep in mind also that you don't have to use "final" characters at the end of words. For example, if a Greek word ends in j, you can type s instead of j. This is done only for convenience sake. The proper final letters will appear in list boxes and text.
You do Greek text (i.e. non-morphological) searches in the same way as English searches. A simple example of a Greek Command Line search might look like this:
|
'pi,steuson evpi. to.n ku,rion VIhsou/n |
Before doing the search you simply change the search version to the appropriate Greek version. You don't have to worry about changing fonts. The Command Line will do that for you.
There are a couple of characters that you will see very rarely in Hebrew text that cannot be entered directly from the keyboard. The first character is the dagesh-Aleph ‚ character which only occurs a couple of times in the Hebrew Old Testament (see Gen. 43:26). To enter it from the keyboard, hold down the <Alt> key and enter the numbers <0130> on the number pad. The second character is used to denote a Hebrew word pair which does not have a Maqqeph between them, but which the Westminster editors decided to treat as a unit for morphological purposes. It appears as a raised dot between the two words when viewed in BibleWorks (see Deu. 10:6 for an example). When exported or printed it appears as a blank space. It can be entered by holding down the <Alt> key and entering the numbers <0131> on the number pad. Note that BibleWorks indexes each word in these pairs separately in the text version (WTT) but as a unit in the morphological version (WTM).
Greek and Hebrew Morphological Searches
Greek and Hebrew Morphological searches are done on morphological constructs consisting of a lemma (dictionary entry) and a morphological code separated by an ‘@’ character (or a ‘%’ character in the case of Aramaic). The codes are used to specify the morphology of the form you are looking for. For a summary of the codes for each language, see the section on Morphological Coding Schemes. See also the examples in the table of Command Line Examples.
There are three additional grouping operators that are defined only inside morphological code sequences. These include parentheses "(" and ")" and the vertical bar character " | ". They are used to group multiple code substring specifications. The " | " acts as an OR operator. For example, the GNM version search
|
.*@((n-) | (ap))* |
will match both *@n-* and *@ap*. It will thus match all nouns and all pronominal adjectives. Don't confuse these parentheses with those used to do compound searches.
There are times when you want to locate lemmas or strings composed of lemmas regardless of their morphology. To do this you could just use the * wildcard as the morphological code. For example, <'pisteuw@*> would find all occurrences of the lemma pisteuw, regardless of morphology. As a convenience, however, if the Command Line parser sees a form without attached morphological codes and you are searching a morphological version, it will automatically attach the @*. Hence the above search could just be written <'pisteuw >. If, for example, you wanted to find all occurrences of the consecutive words "Jesus Christ" in the Greek (regardless of inflection) , you could just enter <'ihsouj cristoj> on the Command Line with GNM as your search version.
Searching on Accents and Vowel Points
Many of the search capabilities of the BibleWorks program require that you enter Greek or Hebrew words on the Command Line. Fortunately you do not have to be switching back and forth all the time between English, Greek and Hebrew fonts. The Command Line in most cases is smart enough to know which font to use and which typing direction is needed. All you have to do is type the words and control characters. The font will change automatically as needed!
The only exception is when you are doing searches on the Hebrew text with vowel point searching activated (see below). In this case there are keyboard conflicts. Some of the Command Line wild cards and control characters are on the same keys as Hebrew vowels. In these cases the Insert key is used as a "dead" key for entering the control characters. The "problem" characters are these:
* ? [ ] { } / . \ ! ( ) ; # @ %
There are two problems associated with the use of these characters. In the case of Greek and Hebrew searches some of these characters are also used for other purposes, i.e. accents or vowel points or other characters. In addition to this, some of these characters do not even appear on some foreign language keyboards. We have tried to come up with a scheme that allows these characters to be entered with minimal fuss. For all searches but accent or vowel point sensitive Hebrew and Greek, all you have to do is type the special character as normal. For vowel point sensitive Hebrew first press the insert key. When you see a red blinking box on the right side of the Command Line type the special character. Then press the insert key again to turn this special input mode off.
Including Vowel Points in Hebrew Searches and Accents in Greek
If you are searching on a Hebrew Text
version or on a Hebrew Morphology version you can tell BibleWorks that you want
to include vowel points in the search. If you are searching on a Greek/Hebrew
Text version or on a Greek/Hebrew Morphology version you can tell BibleWorks
that you want to include accents in the search. This is done by clicking on the
Command Line with the RIGHT mouse button. Choose the appropriate context menu
option to enable or disable vowel point or accent searching. If this option is
active, Search Window Word Lists will include vowel points or accents and you
will also have to include vowel points or accents when you make entries on the
Command Line. In this mode, there is some ambiguity in keyboard usage. Some of
the Hebrew vowels and Greek accents are located on keys normally used to enter
wildcards or grouping and control characters. To solve this problem the <Insert>
key is used as a dead key for entering these control characters.
When you press the <Insert> key, a red blinking light will appear
in the upper right hand corner of the Command Line to indicate that the next
key typed will be a control character. The version label on the button to the
left of the Command Line will have an asterisk after the version label if you
have vowel point or accent searching active. The <Insert> key will
function as described here only when vowel point or accent searching is active
and when a Hebrew or Greek version is the current search version. Keep in mind
that in this mode wildcards will match either vowels or consonants.
Reveal Text Mode
The Command Line can get rather complicated with vowel point entry enabled, because you can easily type multiple vowels on a single consonant and it will not be visible on the screen because the vowel points will be on top of each other. So you may need to take a look at the underlying ASCII text. To do this, press the <Shift-Ctrl-PgDn> key combination. This key combination acts as a toggle to turn the "reveal text" mode on and off.
Morphological Agreement
There is an additional operator which is used only for morphological string searches. If you will not be working with the morphological databases you don't have to concern yourself with it. The operator is an equals sign character followed by one or more "agreement" specifiers. The equals sign can be preceded by a blank or it can be attached directly to the preceding word. If it is preceded by a blank all words that are not pure wild-cards are required to agree in the codes specified. If you attach the operator to the end of words, only words so appended are required to match. The second type of use overrides the first. A single '=' gets its agreement codes from the first full agreement string on the line. For example: <'word1 word2 *3 word3 =gcn> (with a space before the '=') requires that all three words agree in gender, case and number, while the entry string <'word1=gcn word2 *3 word3=gcn> (with no blanks before the '=' signs) requires only that word1 and word3 agree in gender, case and number. The second search could also be written <'word1= word2 *3 word3=gcn> (with no blanks before the '=' signs).
For a specific example, if you set your search version to the Greek New Testament morphological database (GNM) and then enter
|
' anqrwpoj =gcn *9 kaloj |
a search would be made for all verses containing any form of anqrwpoj followed within 9 words in the same verse by any form of kaloj with the restriction that the words agree in gender, case, and number. The characters that you type following the ‘=’ are different for Greek and Hebrew. For Greek you can specify one of more of characters from the set "TVMCGNP", to specify agreement in "Tense, Voice, Mood, Case, Gender, Number or Person". For Hebrew you can specify one or more characters from the set "SAGNP", to specify agreement in "Stem, Aspect, Gender, Number or Person".
Hebrew Morphological Searches - Qere and Kethib codes
Hebrew Morphological searches are done on morphological constructs consisting of a lemma and a morphological code separated by an ‘@’ character (or a ‘%’ character in the case of Aramaic). Every Hebrew morphological code must end in a two-letter code that specifies whether to match words marked as Qere, Kethib, or neither. The codes are the three strings ‘Rq’, ‘Rk’, and ‘Rx’. You can use the square or curly bracket operator to search for combinations. For example, the search string <'*@v*R{qx)> would find all verb forms excluding those with Kethib markers. If you end forms with a wildcard asterisk (‘*’), then all forms will be matched, including Qere, Kethib, and neither.
The Aramaic Article a 'and a e
The Aramaic article a is listed in the WTT BHS
morphology database as
a
' and a e
with the space above the vowel acting as a placeholder
for the word to which the article is attached. Rather than complicate the
search algorithms for this one special case, we have chosen to index and
display these "lemmas" (which they really are not) as a' and ae instead of the forms above. You do not need
to worry about this unless you ever need to enter these lemmas on the Command
Line.
Lemma Agreement and Compound Word Forms
Specifying Lemma Agreement and Compound Word Forms are methods used in Command Line searches to find verses where specific sequences of words in the verse agree in specified morphological codes or in lemma. The Graphical Search Engine is a much better and more powerful mechanism for doing these kinds of searches. We recommend using it instead. The syntax described here predates the introduction of the GSE into BibleWorks. These features have been retained for the sake of users who also predate the GSE and are comfortable with the methods described here. They may also be useful for quick searches when you don't want to go to the extra work involved in constructing a GSE search. Also, a good way to initiate a Lemma Agreement GSE search is to enter it on the Command Line and then open up the GSE, which will then construct the basic search from the Command Line parameters.
If you are doing morphological searches on the Command Line (i.e., your search version is GNM, BLM, BGM, BYM, BNM, TIM, SCM, STM, TAM, JOM, PHM or WTM), you can specify lemma agreement codes. The best way to explain this is with an example. Suppose you wanted to find verses that have the Greek word kai (kai) between two words that have the same lemma, with at most two words between the kai and the two lemmas. The search line that you would enter would look like this: <;#1 *2 kai *2 #1>. The semicolon is used instead of the single quote string search specifier, because in lemma agreement searches, lexical lookup searches are sometimes very slow. This does a linear search. The "*2", as discussed earlier, means skip 2 or less words. The "#1" stands for any lemma whatsoever. The "#1" is duplicated because we want the same lemma to appear on both sides. You can have up to nine different lemmas specified in this way by "#1", "#2", and so on. You could also limit the search by adding the usual morphology code specifiers to the lemmas. For example, if you are searching the GNM version, you might enter <;#1@n-nm* *2 kai *2 #1@n-nm*>. This would do the same search, but require that the lemmas be nouns in the nominative case and masculine gender.
The "#N" operator discussed in the previous section can also have other uses in string search mode. You can define the "#N" operator to stand for a list of words to be included and a list of words to be excluded from the match. This is done by calling up the Define Compound Word Form Window, which is called up via the Command Line Context Menu. Just click on the Command Line with the RIGHT mouse button and choose the "Compound Word Form" option. An alternate way to open this window is to select Tools | Options | Wildcards from the main menu of BibleWorks. In this window you can specify the way the "#N" operator is to be interpreted in linear searches. For details see the Wildcards and Compound Word Forms section.
You can also use the "#N" operator in non-morphological version searches but the behavior is a little different because there are no "lemmas" to deal with. In this case the operator just stands for the same word. For example if you are searching the KJV, the search <;#1 and #1> will find all verses with the same word on either side of the word "and".
The #N operator as discussed in the previous section can be used to limit the matches made by the *N operator. As indicated previously *N will match N or fewer words. If you attach the #N operator to a *N operator it has the effect of limiting the words matched. Thus *N#M (with NO space between the operators) will match any N or fewer words with the restriction that the words must match the inclusion/exclusion lists for the Mth #N operator for the current search version. Normally if you use the operators in this way, you would have the inclusion list to be just a single wildcard.
Context Dependency
Context Dependency in GNM Searches
A few of the morphological forms in the Friberg database (GNM) have a plus sign "+" before or after the form, indicating that there was a relationship between the form and something in its context. If you do not include the "+" in your searches, those forms will not be included. There is an additional operator defined only for Greek New Testament morphological searches which allows you to include forms with and without the plus sign indicator. It is the ampersand operator "&". In general you should include the ampersand at the beginning and end of the morphological codes to specify that forms with and without the "+" will be included. For example: <’poiew@&vn*&>. In other words, the ampersand stands for a "+" or nothing.
Doing Verse Context Sensitive Searches in Hebrew
Doing context sensitive "AND" searches in Hebrew may be a little awkward at first. The reason is that Hebrew words are typed in normal Hebrew style, i.e., right to left. BibleWorks realizes when you are typing a Hebrew word. To facilitate Hebrew word entry, after you enter a letter of a Hebrew word, the text cursor will remain at the left side of the new character after the letter is typed. This permits you to type Hebrew words as you would expect, i.e. from right to left. When you enter a non-Hebrew letter, however, the cursor will be moved to the right of the new character, as for normal English text. The following example will find all verses with the Hebrew words hvm and nrha within 2 verses of each other:
|
. nrha hvm ;2 |
The order in which you type the characters is ".mvh ahrn<End>;2" where the <End> indicates that you press the number pad <End> key to move the cursor to the end of the word before typing the ";2" characters. As an alternative to pressing the <End> key, you can click with the mouse button at the end of the text entry box.
The Morphology Assistant
 If you are doing Command Line searches on the morphological
databases in BibleWorks (the versions labeled GNM, BLM, BNM, BGM, BYM, SCM,
TIM, STM, TAM, JOM, PHM, WTM, and so on), instead of searching on
"words" you will be searching on constructs made up of lemmas and
morphological codes. For example to find all occurrences of the second person
present active imperative of the verb pisteu,w, "to believe", using
the GNM database, you would search for the "word" pisteuw@vmpa--2s.
The "@" sign is just a separator between the lemma and its codes. The
"v" stands for "verb". The "m" stands for
"imperative". The "p" stands for "present". The
"a" stands for "active". And the "2s" stands for
"second person singular". These morphological word constructs are
used just like any other words and in any examples where words are used, these
constructs can be used as well. See An Overview of
Morphological Coding Schemes for a series of Tables showing the coding
schemes for all versions.
If you are doing Command Line searches on the morphological
databases in BibleWorks (the versions labeled GNM, BLM, BNM, BGM, BYM, SCM,
TIM, STM, TAM, JOM, PHM, WTM, and so on), instead of searching on
"words" you will be searching on constructs made up of lemmas and
morphological codes. For example to find all occurrences of the second person
present active imperative of the verb pisteu,w, "to believe", using
the GNM database, you would search for the "word" pisteuw@vmpa--2s.
The "@" sign is just a separator between the lemma and its codes. The
"v" stands for "verb". The "m" stands for
"imperative". The "p" stands for "present". The
"a" stands for "active". And the "2s" stands for
"second person singular". These morphological word constructs are
used just like any other words and in any examples where words are used, these
constructs can be used as well. See An Overview of
Morphological Coding Schemes for a series of Tables showing the coding
schemes for all versions.
![]() For most people the dropdown
selection boxes described above are all the help they need. But other people
need a bit more assistance in learning how to use the morphology codes. The
good news is that BibleWorks has a built-in Morphological Code Assistant which
can construct the codes for you. It is accessed by clicking on the button shown
to the left. Note that this button is not on the toolbar by default but
must be added manually using the Buttonbar Customization
utility.
For most people the dropdown
selection boxes described above are all the help they need. But other people
need a bit more assistance in learning how to use the morphology codes. The
good news is that BibleWorks has a built-in Morphological Code Assistant which
can construct the codes for you. It is accessed by clicking on the button shown
to the left. Note that this button is not on the toolbar by default but
must be added manually using the Buttonbar Customization
utility.
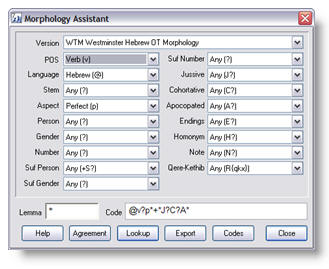
To construct a code you proceed as follows:
· Choose the version you want to work with.
· Choose a part of speech.
· Enter the lemma in the first text box (wildcards are allowed).
· Select a parsing option for each of the drop-down list boxes.
The codes will be constructed automatically and placed in the second text box.
At this point you can click on the "Lookup" button to find all verses
where this form occurs. Or you click on the "Export" button to export
it to the Command Line or Command Line Assistant, where it can be combined with
other words to build more complex search strings.
The Code Assistant window also has a button labeled "Agreement" which
calls up a short window permitting you to set flags to force agreement in
string searches. In searches for only one form, these flags are meaningless,
but they can be very useful for more complex searches.
If you click on the "Codes" button you will be shown a list of all
parsing codes that occur in the version with which you are currently working.
This can be a powerful aid to assist you in learning how to use the codes.